
Chemoinformatics resources
We run local instances of several services focused on Metabolomics, Lipidomics, Statistical analysis and Chemometrics. As the hardware resources are limited, these tools are available only within campus LAN.
All services are running in separate Docker containers:
Metaboanalyst - statistical, functional and integrative analysis of metabolomics data
- Local version based on v4.93, slightly modified to run in Ubuntu 20.04 LTS.
- Few notes on a local standalone installation
- Official service website: https://www.metaboanalyst.ca
MetaboAnalyst in a container.... from https://github.com/xia-lab/MetaboAnalyst_Docker
# modify Docker file # prefer Java 8 (Oracle flavor) ... ENV METABOANALYST_VERSION 4.93 ENV METABOANALYST_LINK https://www.dropbox.com/s/9xo4yy3gzqsvyj9/MetaboAnalyst-4.93.war?dl=0 ENV METABOANALYST_FILE_NAME MetaboAnalyst.war ...
# Build the Dockerfile docker build -t metab_docker . # Run the Dockerfile in the interactive mode docker run -ti --rm --name METAB_DOCKER -p 8080:8080 metab_docker # Execute R script loading libraries etc. inside the container Rscript /metab4script.R # Deploy Java cargo inside the container java -jar /opt/payara/payara-micro.jar --deploymentDir /opt/payara/deployments # Look for running MetaboAnalyst at http://localhost:8080/MetaboAnalyst/
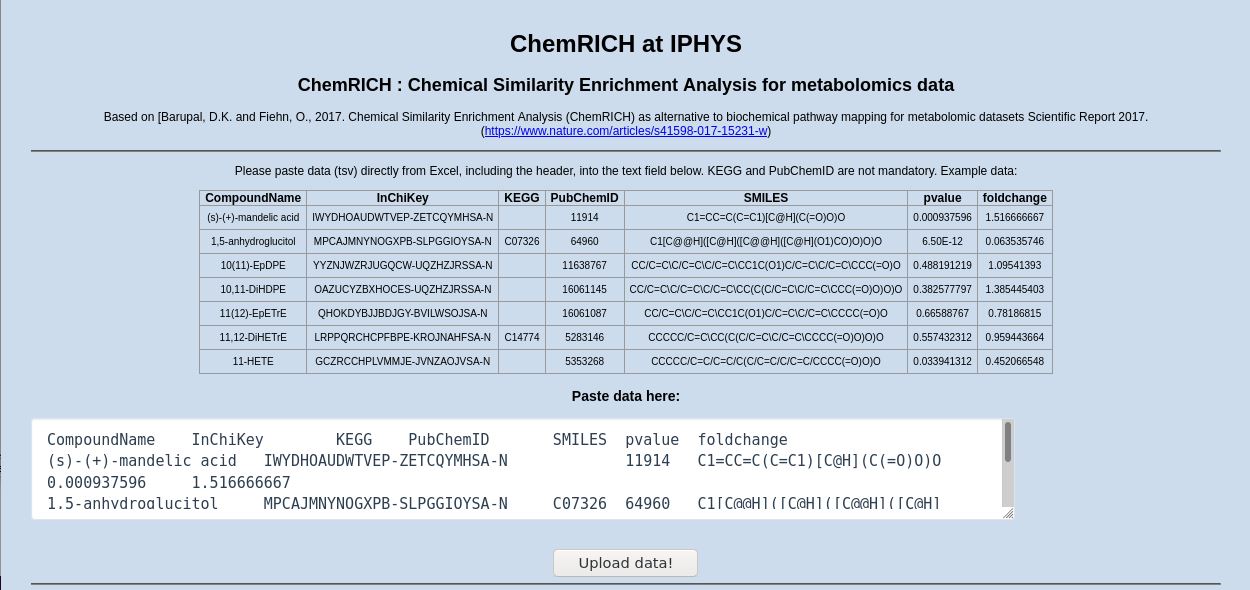
ChemRICH - Chemical Similarity Enrichment Analysis for Metabolomics
- Local version based on latest git version, modified to run in Ubuntu 20.04 LTS (R 4.0+)
- Corrected output formats, fixed compatibility issues and added SVG export option
- Official service website: http://chemrich.fiehnlab.ucdavis.edu
# Dockerfile
FROM opencpu/base
MAINTAINER OK
LABEL Description = "ChemRICH 0.1.1 container"
...
# prepare Ubuntu for compilations as needed
...
# setup Java, jdk contains jre, set PATH
RUN apt-get -y install openjdk-11-jdk
# check where is Java
#RUN update-java-alternatives -l
#RUN java -version
ENV JAVA_HOME="/usr/lib/jvm/java-1.11.0-openjdk-amd64"
ENV PATH $JAVA_HOME/bin:$PATH
# configure Java for R
RUN R CMD javareconf
RUN R -e "install.packages('rJava', repos='http://cran.rstudio.com/')"
# install all R packages via R script, wait few hours
# XLConnect works with Java 8 till Java 11, no more
ADD install_package.R /install_package.R
RUN Rscript install_package.R
# these packages require special attention
# RCurl needs re-installation if ....rcurl.so... error appears
RUN R -e "install.packages('devtools', repos='http://cran.rstudio.com/')"
RUN R -e "install.packages('RCurl', repos='http://cran.rstudio.com/')"
RUN R -e "install.packages('unix', repos='http://cran.rstudio.com/')"
# run local installation of the package
COPY ChemRICH_0.1.1.tar.gz /ChemRICH_0.1.1.tar.gz
RUN R -e "install.packages('ChemRICH_0.1.1.tar.gz', repos = NULL)"
# opencpu needs more time for POST and more memory, upload modified configurations (timelimit.post": 900, etc.)
COPY defaults.conf /usr/local/lib/R/site-library/opencpu/config/defaults.conf
COPY server.conf /etc/opencpu/server.conf
# make sure Java can be found in rApache and other daemons not looking in R ldpaths
# otherwise RJava loading error will appear
RUN echo "/usr/lib/jvm/java-1.11.0-openjdk-amd64/lib/server/" > /etc/ld.so.conf.d/rJava.conf
RUN /sbin/ldconfig
# add R script if needed in the interactive session
ADD run-opencpu-server.R /run-opencpu-server.R
# start the service
CMD service cron start && /usr/lib/rstudio-server/bin/rserver && apachectl -DFOREGROUND
# just in case
# ENTRYPOINT ["bin/bash"]
Build and run the container
docker run -t -p 80:80 -p 8004:8004 opencpu/rstudio # help: https://hub.docker.com/r/opencpu/rstudio # help: https://opencpu.github.io/server-manual/opencpu-server.pdf # browse # http://localhost:8004/ocpu/library/ChemRICH/www/ # http://localhost:8004/ocpu/info
CRediT (Contributor Roles Taxonomy) generator
This web generator helps to summarize contributions of individual authors and prepare the Author contributions paragraph for a scientific journal
MS-DIAL data processing benchmark
The purpose of this test was to select an appropriate hardware for LC-MS data processing using MS-DIAL 4.20.
Input data
- Metabolomics profiling using LIMeX5D workflow. Only HILICn part was selected.
- Q Exactive Plus; R17,500; 714 *.abf files, each ~5 MB
- Time windows of 6 minutes selected for data processing.
- Custom MSP metabolomics library, 1.5 GB
HW resources
Machine A - old office computer
- Intel Core i3 4130 (2 CPU/4 threads)
- DDR3 8 GB
- SSD 6 Gb/s
- Windows 10 Pro 64bit
Machine B - Workstation
- AMD Ryzen 7 7200X (8 CPU/16 threads)
- DDR4 64 GB
- NVMe 4x 8.0 GT/s
- Windows 10 Pro 64bit
Machine C - Virtual machine (OpenStack)#
- virtual Intel Xeon-2296 (16 vCPUs)
- 64 GB
- QEMU HDD
- Windows Server 2019
Results
| Machine | MS-DIAL threads | Intensity threshold | Library loading... | Peak detection... | Alignment... | Total time | Peak spots |
|---|---|---|---|---|---|---|---|
| A | 4 | 20,000 cps | 20 min | 90 min | 260 min | 6.2 hrs | 23,840 |
| B | 4 | 20,000 cps | 20 min | 34 min | 37 min | 1.5 hrs | 23,840 |
| B | 8 | 20,000 cps | 20 min | 27 min | 42 min | 1.5 hrs | 23,840 |
| B | 16 | 20,000 cps | 20 min | 23 min | 40 min | 1.4 hrs | 23,840 |
| B | 16 | 20,000 cps | 1 min* | 23 min | 36 min | 1.0 hrs | 23,840 |
| C | 16 | 20,000 cps | 23 min | 14 min | 46 min | 1.4 hrs | 23,840 |
| C | 16 | 20,000 cps | 1 min* | 14 min | 45 min | 1.0 hrs | 23,840 |
| C | 16 | 1,000 cps | 23 min | 30 min | 920 min | 16.2 hrs | 27,026 |
- Processor: More threads means faster data processing, mainly in the middle part. New CPUs beat older versions. Number of available threads per physical CPU is not equivalent to the number of VCPUs as it depends on the virtualization.
- Memory: Peak memory usage was ~ 25 GB during the alignment phase. The final alignmentResult_2020_6_6_22_21_59.EIC.aef file was ~14 GB. At least 1.5 GB RAM per thread was needed. If RAM amount was limited, memory caching to disk prolonged the processing significantly (not shown, run scratched after 6 hrs).
- Disk: no major difference was observed between SSD, NVMe, and emulated virtual drive. The final part of data merging run at ~35 Mb/s writing.
- If no Threadripper workstation is available, virtualization could help. Physical machine B and virtual machine C performance was comparable. However, B was faster in parts where a direct hardware access was needed - and C was faster in parallel processing thanks to dedicated 16vCPUs. A general estimation is that 1 vCPU = 1 Physical CPU Core. However, this is not entirely correct, as the vCPU is made up of time slots across all available physical cores, so in general 1vCPU is actually more powerful than a single core, especially if the physical CPUs have 8 cores. Therefore, AMD workstation with 8 CPUs kept pace with 16vCPUs.
- When peak picking threshold was set to very low level (1,000 cps), only ~3,200 more spots were found for extra 14.8 hours. Most of the extra spots were unreliable and within the noise level.
- * The initial Library loading takes a constant amount of time. However, once processed and serialized, an *.msp2 binary file is created. This could be re-used in an independent project as an MSP library that is loaded within a minute. Therefore, the minimal time of analysis was 1.0 hr.
- # Computational resources were supplied by the project "e-Infrastruktura CZ" (e-INFRA LM2018140) provided within the program Projects of Large Research, Development and Innovations Infrastructures.
Conclusion
Dedicated physical workstation with many CPUs (Threadripper or better) is the best option for processing large datasets with large libraries using MS-DIAL software.